中山大学软件工程数据挖掘第二次作业
github地址:https://github.com/linjiafengyang/DataMining
模型的性能度量
我们需要比较两个分类模型M_1和M_2。他们在10个二类(+或-)样本所组成的测试集上的分类结果如下表格中所示。假设我们更关心正样本是否能被正确检测。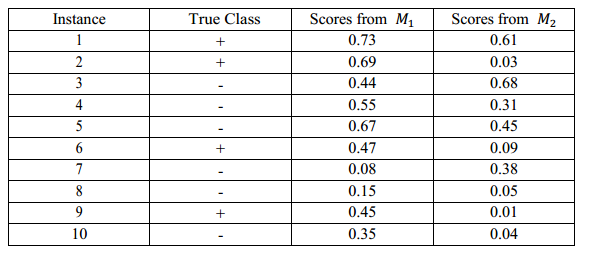
(1)对于分类模型M_1,取阈值为0.5,分别计算分类准确率(accuracy)、查准率(precision)、查全率(recall,又称真正例率,true positive rate,TPR)、假正例率(false positive rate,FPR)和F-measure;
(2)对于分类模型M_2,取阈值为0.5,分别计算分类准确率(accuracy)、查准率(precision)、查全率(recall,又称真正例率,true positive rate,TPR)、假正例率(false positive rate,FPR)和F-measure;并与分类模型M_1比较,分析哪个分类模型在这个测试集上表现更好;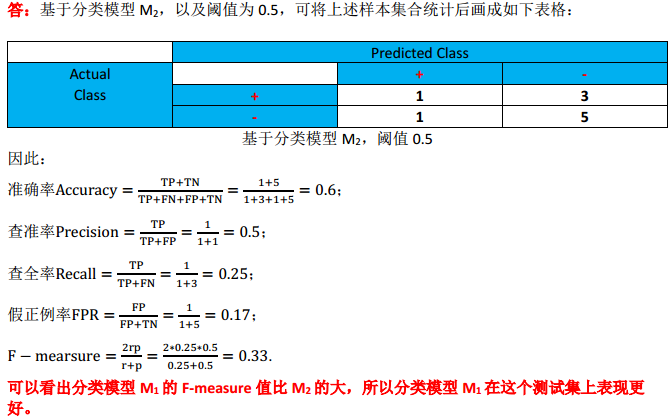
(3)对于分类模型M_1,取阈值为0.2,分别计算分类准确率(accuracy)、查准率(precision)、查全率(recall,又称真正例率,true positive rate,TPR)、假正例率(false positive rate,FPR)和F-measure;并讨论当阈值为0.2或0.5时,哪个分类模型M_1的分类结果哪个更好;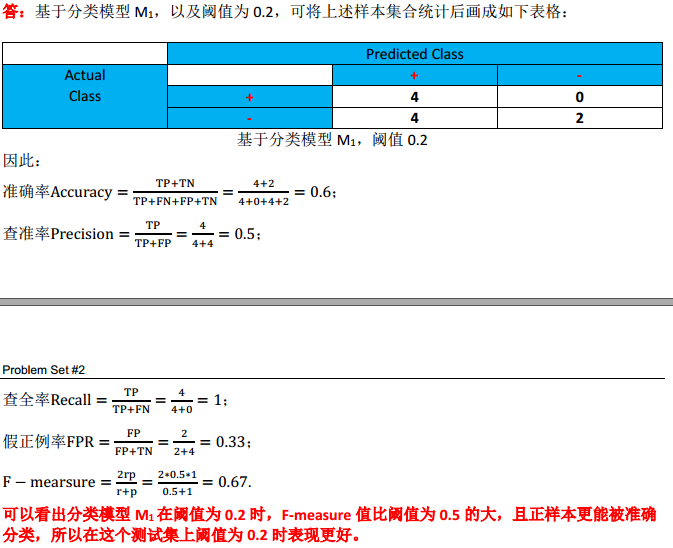
(4)试讨论是否存在更好的阈值;若存在,请求出最优阈值并说明原因。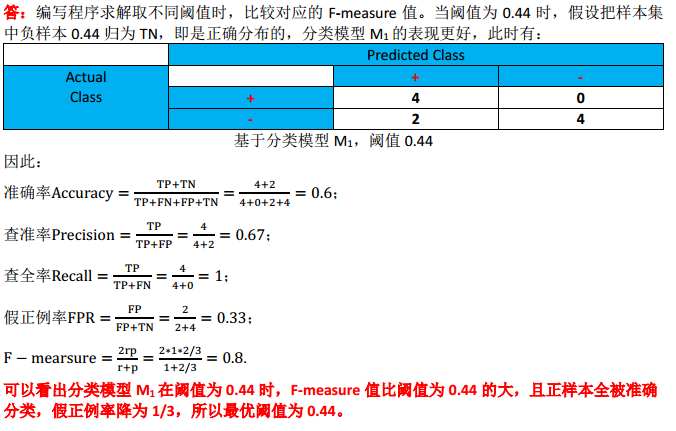
神经网络
考虑以下的二类训练样本集:
对此训练样本集,我们需要训练一个三层神经网络(输入层、单隐层、输出层),其中单隐层的单元(神经元)数目设为2,激活函数(activation function)为Sigmoid函数:
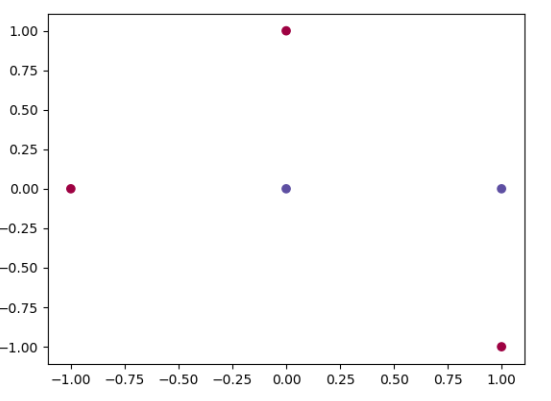
(1)在二维坐标系中画出这5个训练样本点,并讨论此训练样本集是否线性可分;
答:如下图画出这5个训练样本点:从图中可观察出该训练样本集非线性可分,无法找到一条直线可以完全准确地把这5个训练样本点分类。
(2)试分析将Sigmoid激活函数换成线性函数的缺陷;
答:如果激活函数换成线性函数,那么无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层的效果相当,就成了最原始的感知器了,与不使用激活函数、直接使用逻辑回归没有区别。
(3)令初始化参数全部为0,试运用前馈(feedforward)算法计算在初始化参数下此三层神经网络的输出;然后运用反向传播(backpropagation)算法,计算代价函数对所有参数的偏导数,并讨论将初始化参数全部设为0所带来的问题;
初始化参数不能全部设为0的原因:如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值,那么隐藏神经元对输出单元的影响也是相同的,通过反向传播梯度下降法进行计算时,会得到同样的梯度大小,所以无论设置多少个隐藏单元,其最终的影响都是相同的。同理,也不能初始化所有的参数都为同一个非0的数。因此,要随机化初始参数,以打破对称性。
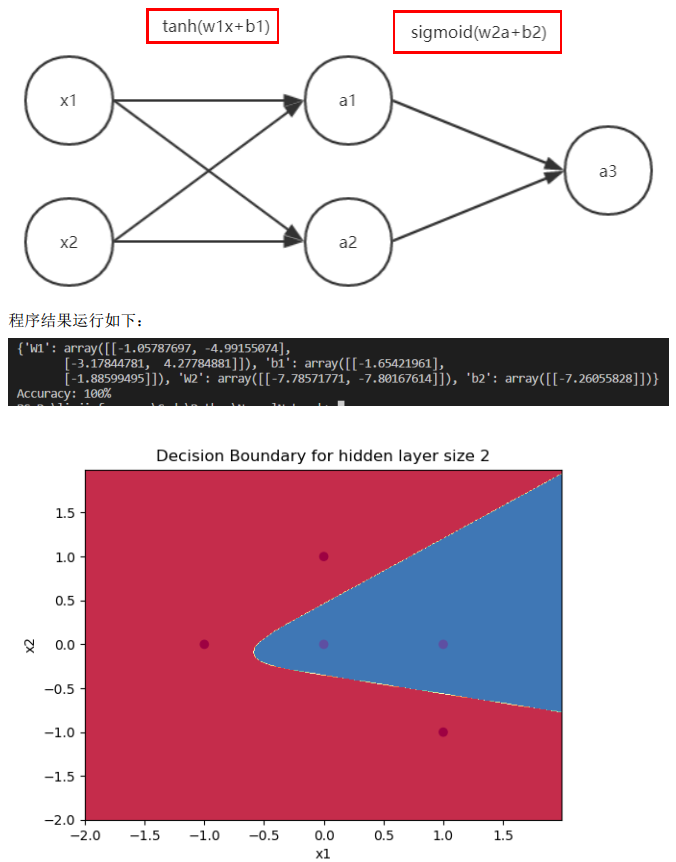
(4)试给出一个神经网络(画出架构图,并写出激活函数及其对应的参数),使此训练样本集的5个训练样本点都可以被正确分类。
答:采用如下的神经网络,输入层到隐藏层采用tanh激活函数,隐藏层到输出层采用sigmoid激活函数。
训练后如下参数可以使样本集都可以被正确分类:
w1=[[-1.05787697, -4.99155074], [-3.17844781, 4.27784881]],;
b1=[[-1.65421961], [-1.88599495]];
w2=[[-7.78571771, -7.80167614]];
b2=[[-7.26055828]].
决策树
考虑以下的二类训练样本集: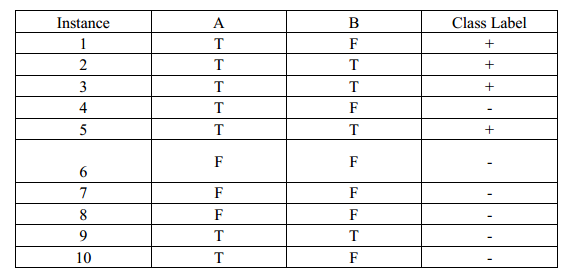
(1)计算以属性A或B为划分的信息熵(Entropy)增益,并说明决策树学习算法选择哪个属性进行划分;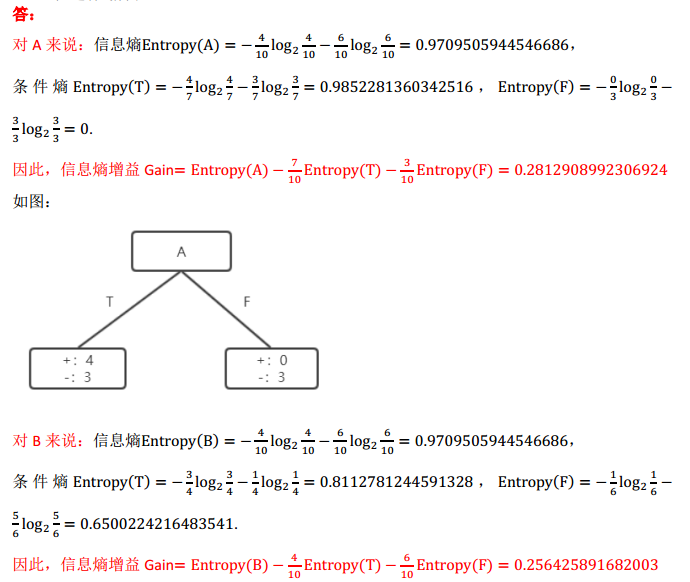
(2)计算以属性A或B为划分的Gini增益,并说明决策树学习算法选择哪个属性进行划分;
(3)计算以属性A或B为划分的分类误差(Classification Error)增益,并说明决策树学习算法选择哪个属性进行划分;
(4)说明信息熵增益、Gini增益和分类误差增益对属性选择有不一样的偏好。
答:(吹水。。)
信息熵增益:当子结点的加权平均熵越小,表示再往下分支越容易,或者说当前特征提供的信息量越多。信息熵针对分类中的属性。然而,在各个特征的可能取值不同时,比如有些特征只有0/1取值,而有些特征可以有几十种取值,信息熵容易选择一个取值很多的特征,导致过拟合。除此之外,在多分类问题中,信息熵增益存在大量的log计算,因此计算复杂度倍增。在二分类问题中表现突出。
Gini增益:如果这个结点是个叶子结点,从中随机取一个数据,并按该结点中各类数据的分布随机地预测一个类别,预测错误的概率。Gini系数是针对较为连续的属性,最小化错分率。Gini不像信息熵计算复杂,因此效率方面很高。
分类误差增益:和Gini增益大同小异。